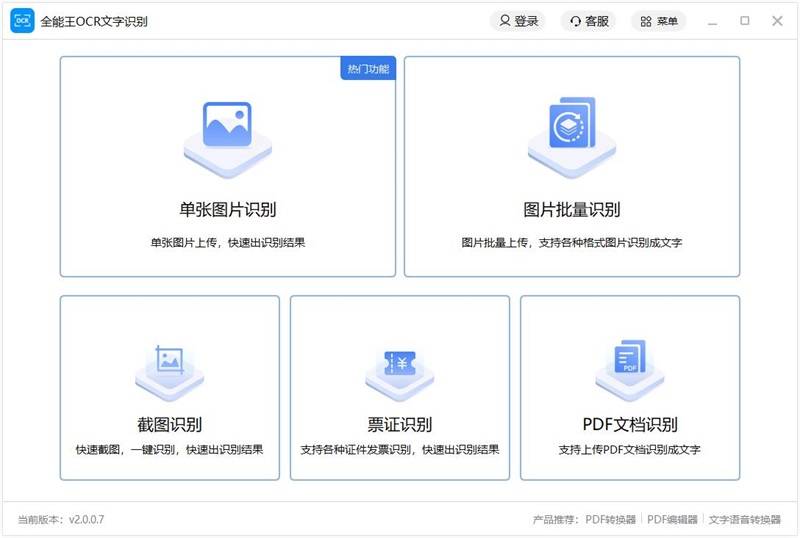
全能王OCR 文字识别是一种专业且多功能的桌面工具,用于识别图片和 PDF 文本。软件提供了单张图片识别、图片批量识别、截图识别、票证识别、PDF文档识别五大主体功能,支持用户自主设置输出格式、转换格式和输出路径等参数,从而获得理想的识别效果。且支持批量操作功能,用户可以批量添加要压缩的文件或者文件夹,并支持直接拖拽文件到压缩列表,非常的便捷操作。它完美地工作在您的 Windows 和 Mac 计算机上。
目录
下载
要使用此程序识别图片和 PDF 文本,请单击下面的按钮以下载并在计算机上安装程序。
OCR 文字识别的主窗口:
单张图片识别
在这里,我们将向您展示如何单张图片识别的详细步骤。
1. 打开程序,点击”单张图片识别”选项。
2. 拖动要识别的文件,或点击”添加文件”以添加文件。单张图片识别一次只能添加或者拖拽一张图片。
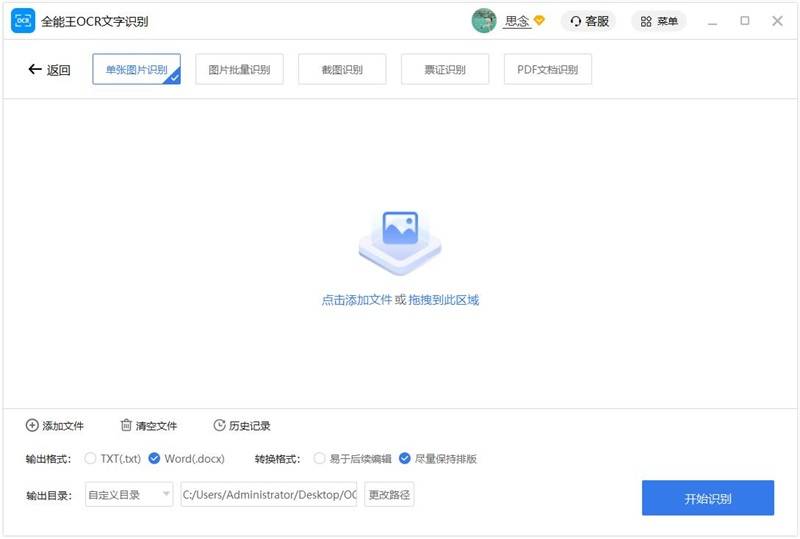
3. 设置您想要的转换参数和输出目录。
输出格式:可选择TXT或Word。
转换格式:可选择易于后续编辑或尽量保持排版。
输出目录:可选择原文件目录或自定义目录。
4. 点击”开始识别”按钮进行单张图片识别。
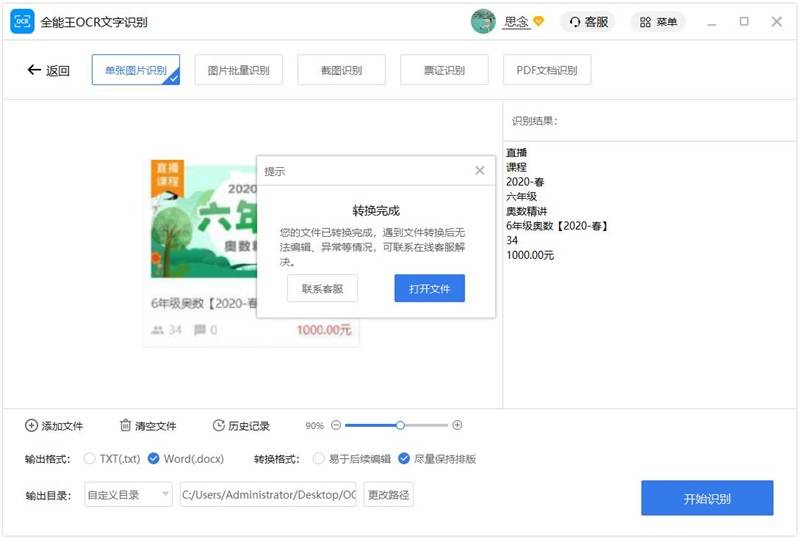
5. 转换完成后,您可以点击”打开文件”按钮查看已识别的文件。如转换过程中有问题,可点击“联系客服”按钮。
图片批量识别
在这里,我们将向您展示如何图片批量识别的详细步骤。
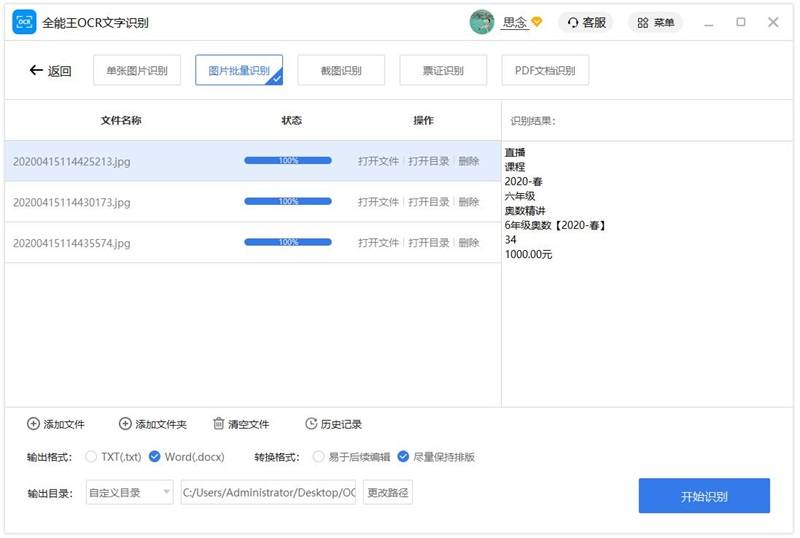
1. 打开程序,点击”图片批量识别”选项。
2. 拖动要识别的文件,或点击”添加文件”以添加文件。 图片批量识别一次可添加或者拖拽多张图片。
3. 设置您想要的转换参数和输出目录。
输出格式:可选择TXT或Word。
转换格式:可选择易于后续编辑或尽量保持排版。
输出目录:可选择原文件目录或自定义目录。
4. 点击”开始识别”按钮进行图片批量识别。
5. 转换完成后,您可以点击”打开文件”按钮查看已识别的文件。如转换过程中有问题,可点击“联系客服”按钮。
截图识别
在这里,我们将向您展示如何截图识别的详细步骤。
1. 打开程序,点击”截图识别”页签。
2. 点击”点击截图”按钮进行截图,或使用快捷键”ALT+F”进行屏幕截图。
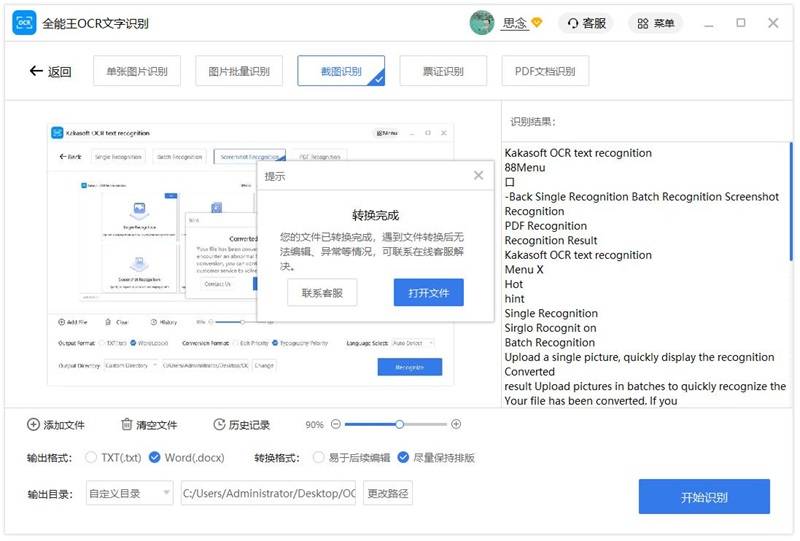
3. 设置您想要的转换参数和输出目录。
4. 点击”开始识别”按钮进行截图识别。
5. 识别完成后,您可以点击”打开文件”按钮查看已识别的文件。如转换过程中有问题,可点击“联系客服”按钮。
票证识别
在这里,我们将向您展示如何票证识别的详细步骤。
1. 打开程序,点击”票证识别”页签。
2. 票证识别提供身份证、银行卡、营业执照、驾驶证、火车票、发票等多种可供选择的票证类别。
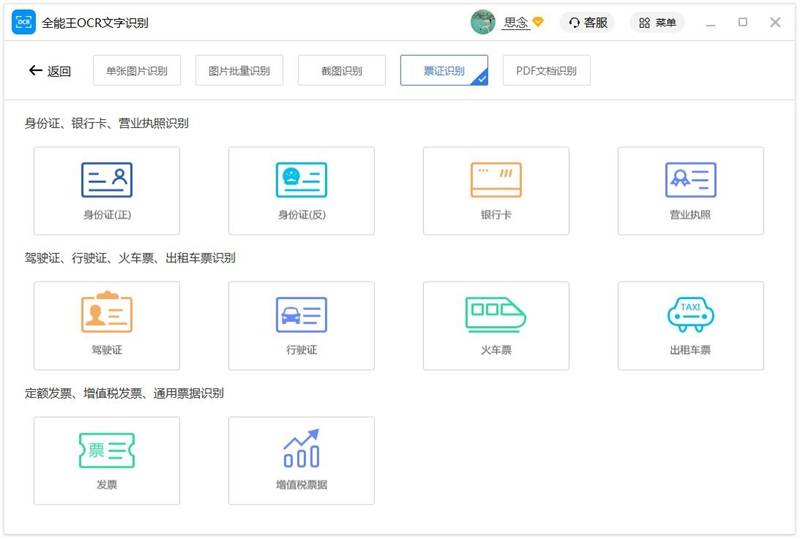
3. 选择某一个票证类别(此处我们以身份证举例)。 拖动要识别的文件,或点击”添加文件”以添加文件 。
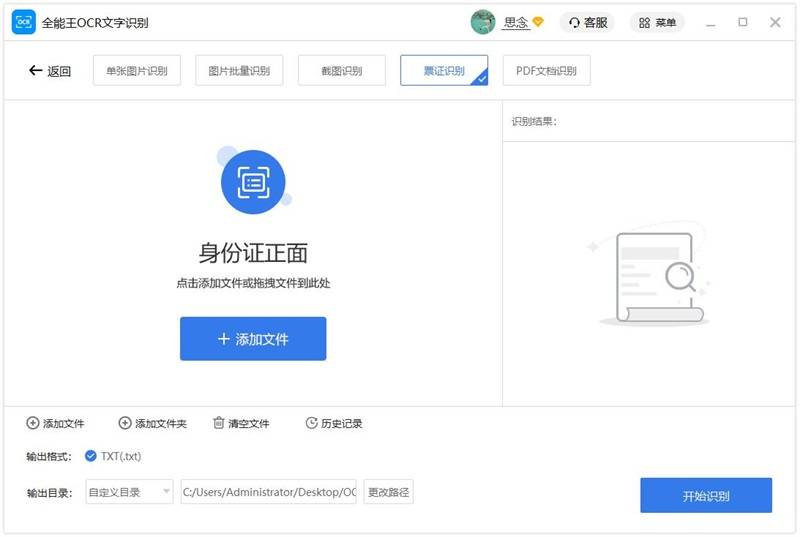
4. 设置您想要的转换参数和输出目录。
输出格式:只能选择TXT格式。
输出目录:可选择原文件目录或自定义目录。
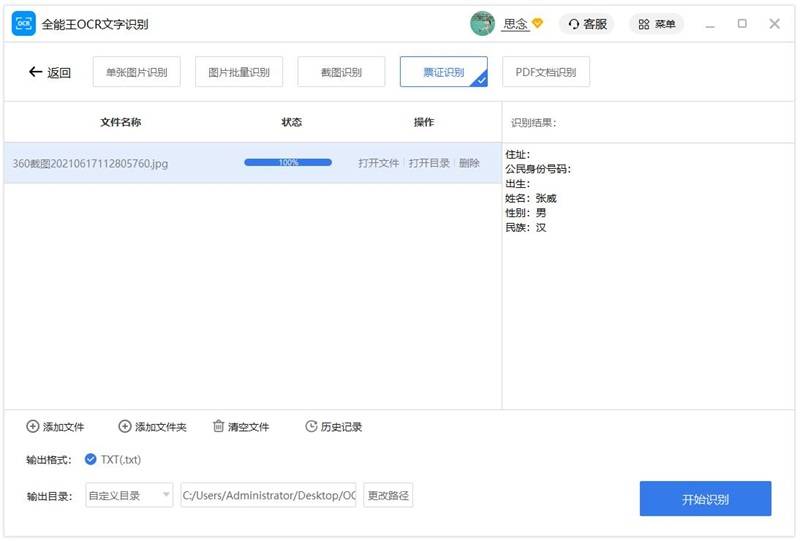
5. 点击”开始识别”按钮进行票证识别。
6. 识别完成后,您可以点击”打开文件”按钮查看已识别的文件。如转换过程中有问题,可点击“联系客服”按钮。
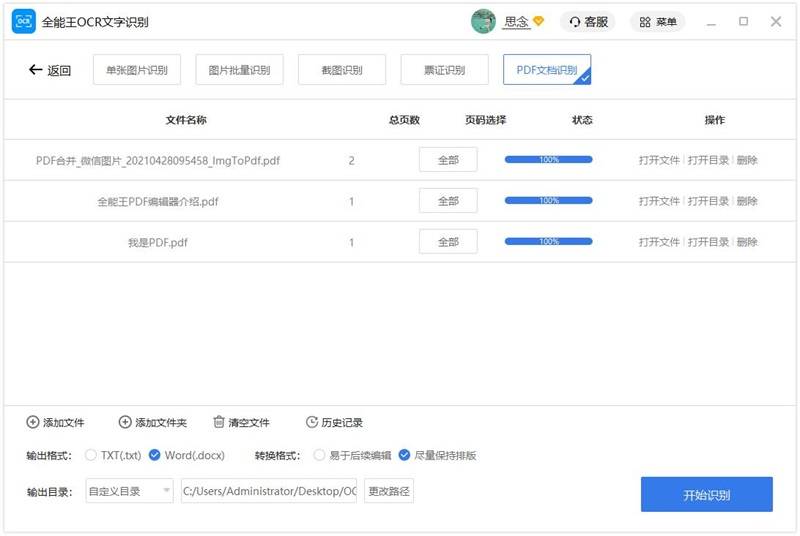
PDF文档识别
在这里,我们将向您展示如何PDF文档识别的详细步骤。
1. 打开程序,选择”PDF文档识别”页签。
2. 拖动要识别的文件,或点击”添加文件”以添加文件。
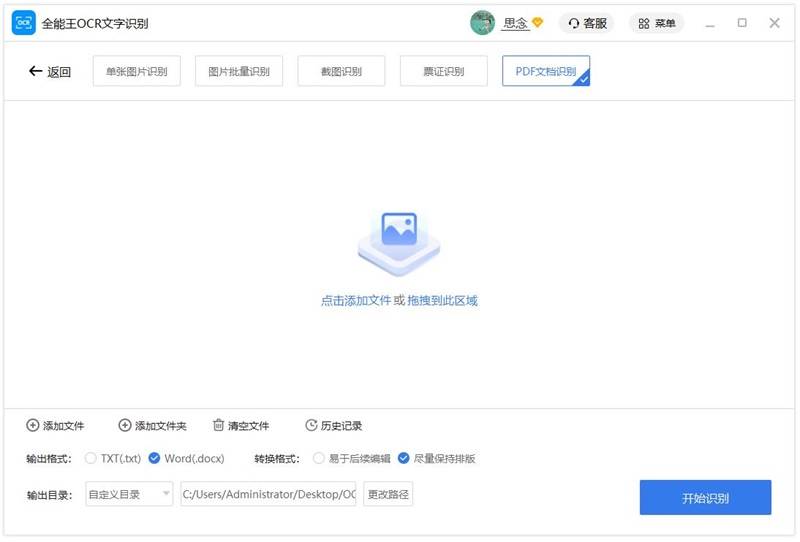
3. PDF文档识别一次可添加或者拖拽一个或多个PDF文档。
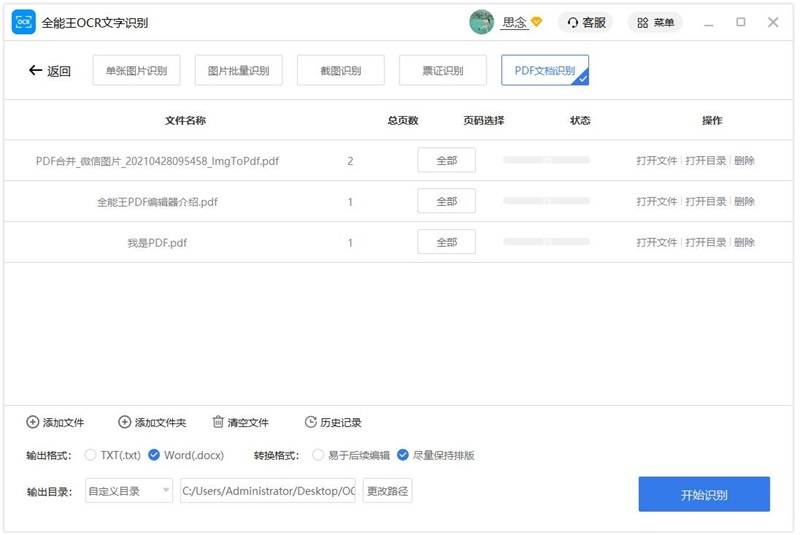
4. 页码选择点击“全部”可自定义设置要转换的页码。
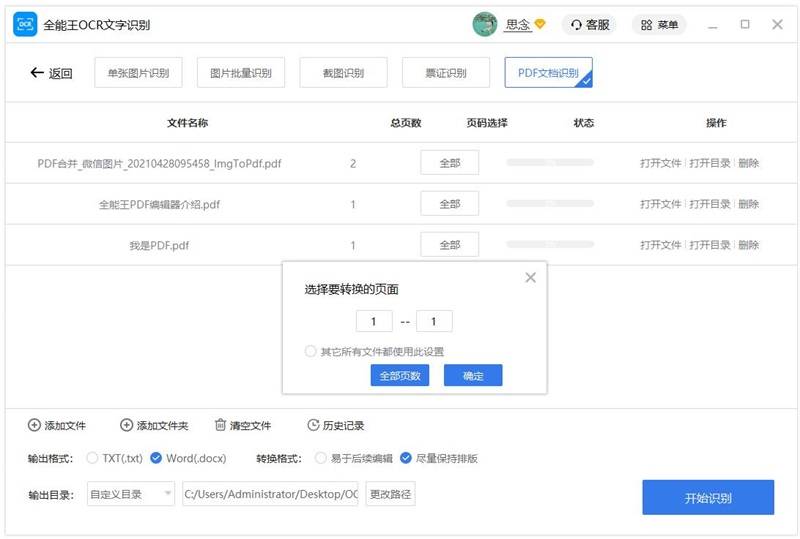
5. 设置您想要的转换参数和输出目录。
输出格式:可选择TXT或Word。
转换格式:可选择易于后续编辑或尽量保持排版。
输出目录:可选择原文件目录或自定义目录。
6. 点击”开始识别”按钮进行PDF文档识别。
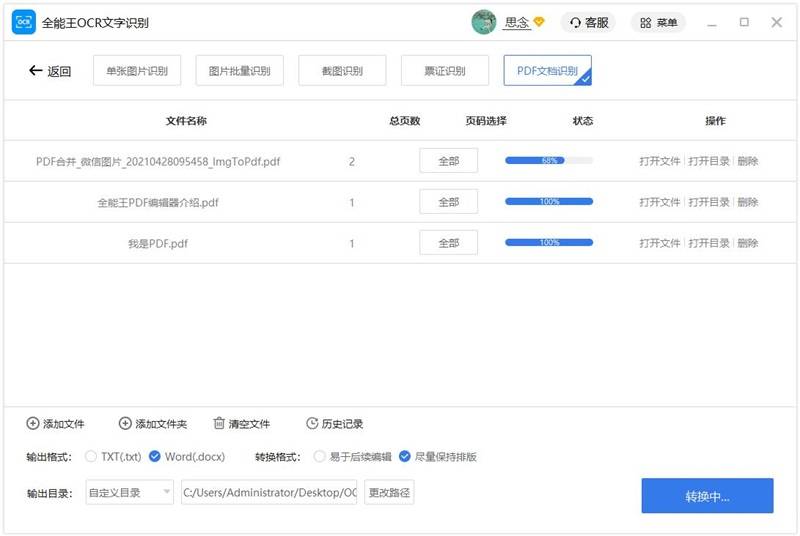
7. 识别完成后,您可以点击”打开文件”按钮查看已识别的文件。如转换过程中有问题,可点击“联系客服”按钮。